


How to Build an End to End Data Pipeline Project Using Mage, dbt, PostgreSQL, and Power BI
Part 4: Enhancing Data Workflows and Data Quality with dbt Seeds

Introduction
Are you struggling to manage reference tables in your data pipelines? Within the dbt ecosystem, a feature that is often used to solve this issue is dbt seeds.
This article will explore dbt seeds in depth, discussing their purpose, implementation, best practices, and how they fit into the broader context of data workflows, including a tutorial on importing seed data files in your Mage Chicago Crime Analytics project.
What are dbt Seeds
At their core, dbt Seeds are CSV files that you can incorporate into your dbt project. These ‘seeds’ can be referenced in your models just like any other table in your data warehouse. They are particularly valuable for small, static datasets that don't undergo frequent changes and are typically maintained by analysts or other team members.
The process of using dbt Seeds is straightforward. When you run the dbt seed command, dbt reads the CSV files located in your ‘seeds’ directory and loads them into your data warehouse as tables. From there, these seed tables can be referenced in your dbt models just like any other table.
To implement dbt Seeds in your project, you start by creating a ‘seeds’ directory within your dbt project structure. Next, you place your CSV files in this newly created directory. Running ‘dbt seed’ will then load the CSV data into your data warehouse. Finally, you can reference these seed tables in your dbt models using the {{ ref(‘seed_name’) }} syntax. It's a simple yet powerful workflow that can significantly streamline your data processes.
How dbt Seeds Improve your Project
Use dbt seeds to help with the following:
Version Control for Static Data: By keeping static data in your dbt project, you ensure it's version-controlled alongside your dbt models.
Easy Updates: When changes are needed, you can simply update the CSV file and re-run your dbt project.
Consistency Across Environments: Seeds ensure that all environments (development, staging, production) use the same static data.
Using dbt Seeds in your Mage Project
Seeds can be uploaded into your dbt project within Mage. To do this you will need to complete the following steps:
Go to the the Chicago data portal and download the neighborhoods dataset
Click the export button and then select CSV as your download
Create a subfolder for your seeds, for instance mine is called mage_chicago_crimes
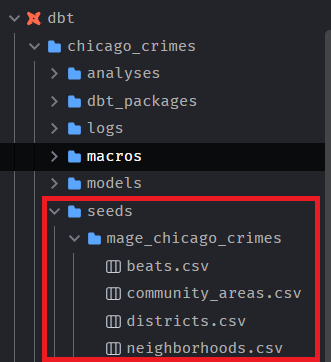
Right or control click on the subfolder and then select Upload file
When the pop up below appears click into the box for drop your file in to upload

The popup below will appear to let you know the file is loading into it’s location

Once your file loads you will be able to connect it through SQL / JINJA in your other models.
Add the code below to your dbt_project.yml file
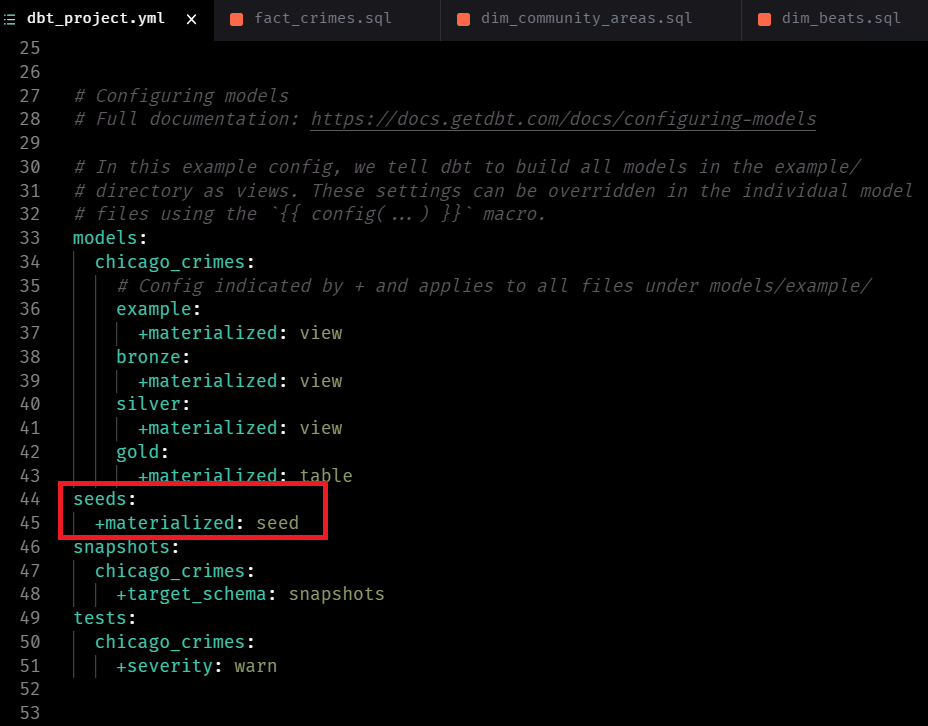
Note: Next week we will run the seed files along with our other models in this project.
Conclusion
dbt seeds are a powerful feature that enhances data workflows by providing a simple, version-controlled way to manage static reference data. By using seeds effectively, data teams can improve data consistency, simplify testing, and create more robust data transformations.
While seeds are not suitable for all types of data, they excel in managing small, infrequently changing datasets that are crucial for data transformations and analysis. When used in conjunction with other dbt features and integrated into data orchestration platforms like Mage AI, seeds become part of a comprehensive approach to building reliable, maintainable data pipelines.
Want to learn more, next week we will be discussing dimensional data modeling and the Chicago Crimes Analytics project.
If you are just finding this Substack take a look at my previous series articles.
Part 1: Analytics Infrastructure Setup